DistributedDataParallel non-floating point dtype parameter with requires_grad=False · Issue #32018 · pytorch/pytorch · GitHub
🐛 Bug Using DistributedDataParallel on a model that has at-least one non-floating point dtype parameter with requires_grad=False with a WORLD_SIZE <= nGPUs/2 on the machine results in an error "Only Tensors of floating point dtype can re

Getting Started with PyTorch Distributed

Torch 2.1 compile + FSDP (mixed precision) + LlamaForCausalLM
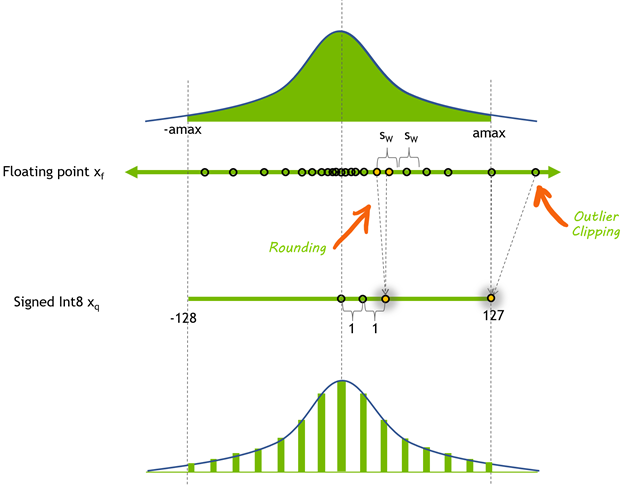
Achieving FP32 Accuracy for INT8 Inference Using Quantization

Wrong gradients when using DistributedDataParallel and autograd

Distributed Data Parallel and Its Pytorch Example

Achieving FP32 Accuracy for INT8 Inference Using Quantization

PyTorch tensors debunked. PyTorch is a python library created to
Don't understand why only Tensors of floating point dtype can

Cannot update part of the parameters in DistributedDataParallel