Pre-training vs Fine-Tuning vs In-Context Learning of Large

Large language models are first trained on massive text datasets in a process known as pre-training: gaining a solid grasp of grammar, facts, and reasoning. Next comes fine-tuning to specialize in particular tasks or domains. And let's not forget the one that makes prompt engineering possible: in-context learning, allowing models to adapt their responses on-the-fly based on the specific queries or prompts they are given.

The overview of our pre-training and fine-tuning framework.

Cameron R. Wolfe, Ph.D. on X: Recent language models have heavily emphasized automatic collection of training data, either from other models or via frameworks like self-instruct. But, this approach is probably not

How does in-context learning work? A framework for understanding the differences from traditional supervised learning
What Is Transfer Learning? [Examples & Newbie-Friendly Guide]
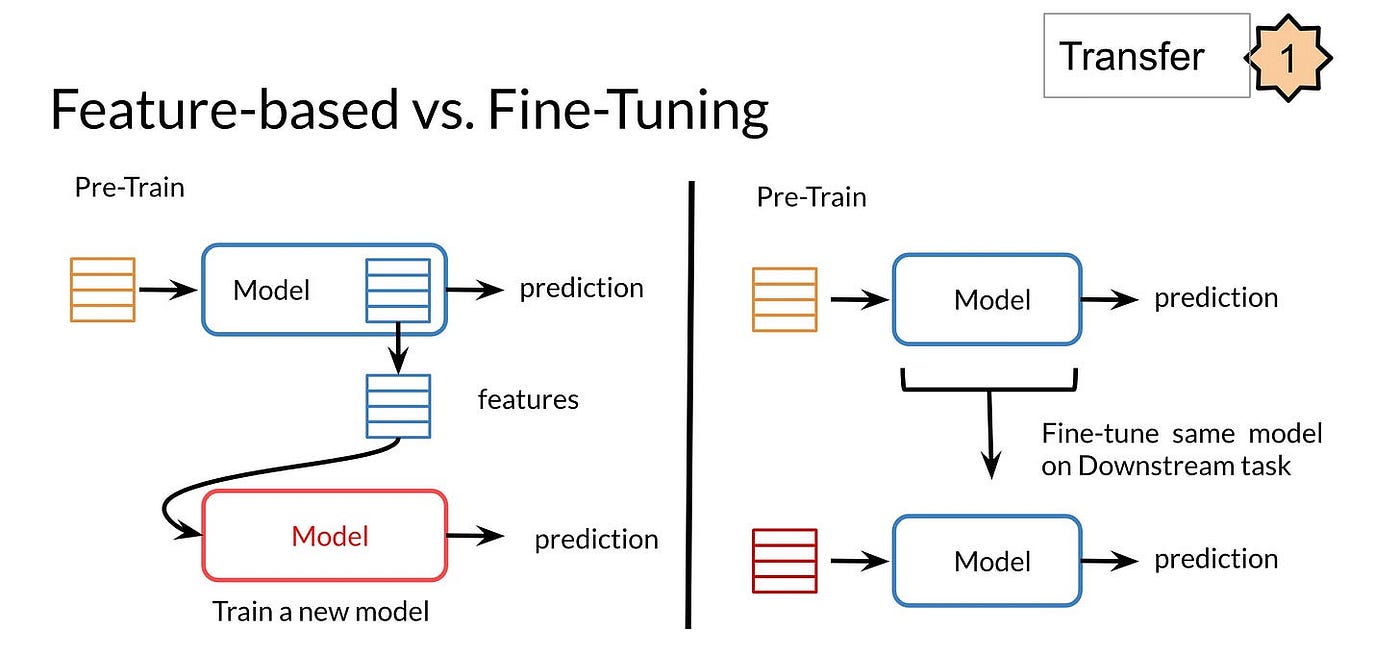
Feature-based Transfer Learning vs Fine Tuning?, by Angelina Yang

Comparisons between the in-context learning and finetuning paradigms

In-Context Learning Approaches in Large Language Models, by Javaid Nabi
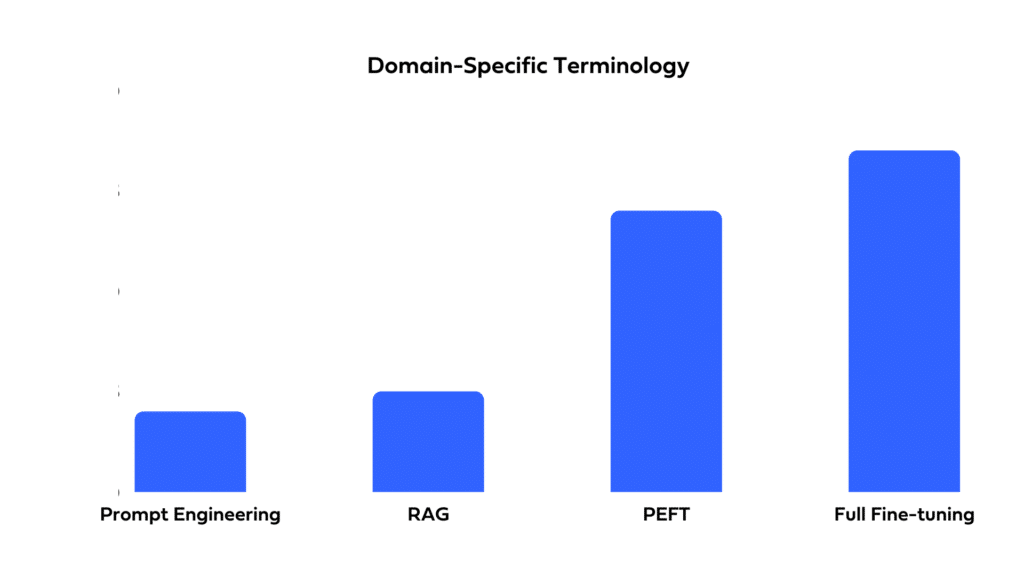
Full Fine-Tuning, PEFT, Prompt Engineering, or RAG?

Articles Entry Point AI

In-Context Learning, In Context

In-Context Learning and Fine-Tuning for a Language Model







