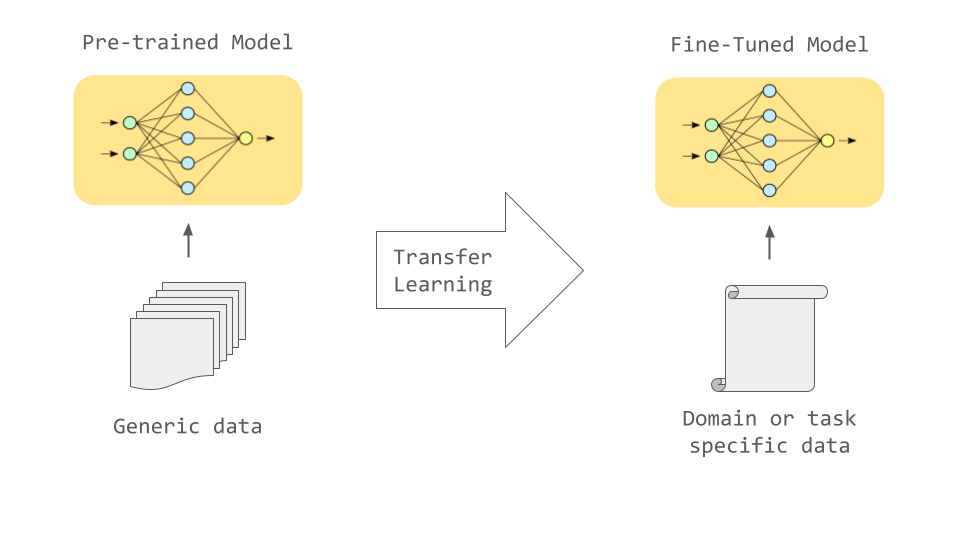
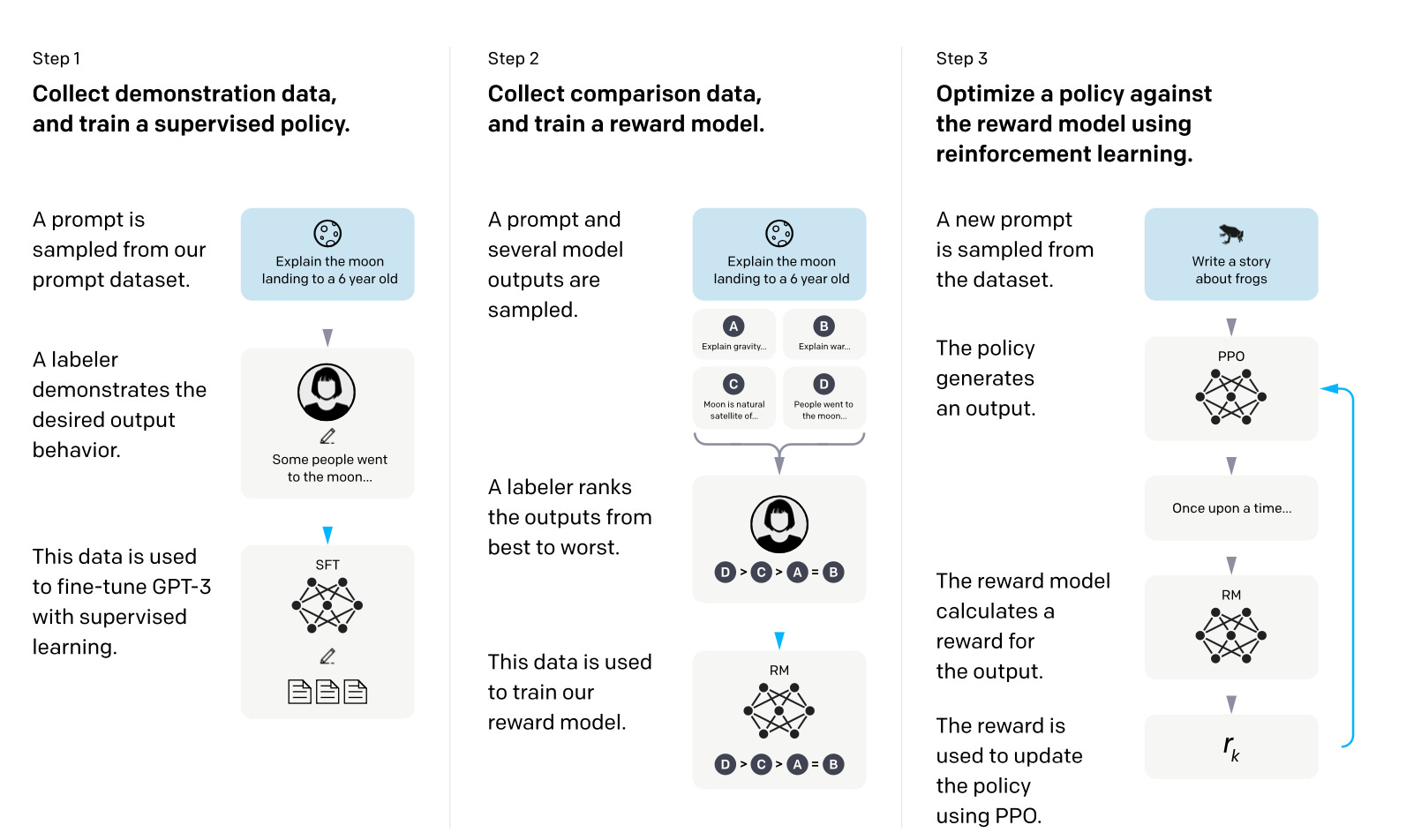
We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on

PDF) Vision Models Can Be Efficiently Specialized via Few-Shot Task-Aware Compression

NeurIPS 2023

2301.02240] Skip-Attention: Improving Vision Transformers by Paying Less Attention

D] Why Vision Tranformers? : r/MachineLearning

PDF] ConvNeXt V2: Co-designing and Scaling ConvNets with Masked

PDF] ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
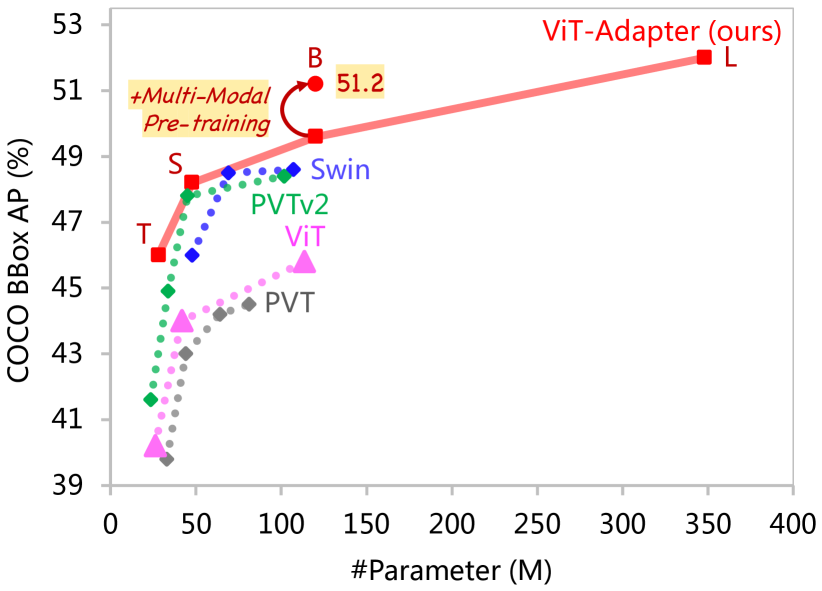
2205.08534] Vision Transformer Adapter for Dense Predictions
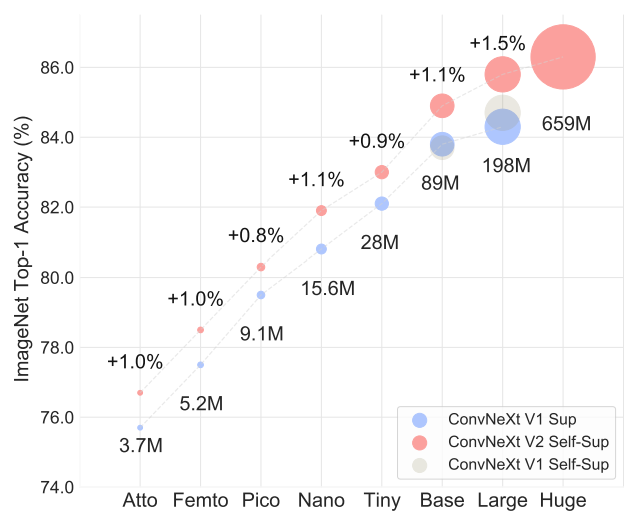
Papers Explained 94: ConvNeXt V2. The ConvNeXt model demonstrated strong…, by Ritvik Rastogi, The Deep Hub
The Computer Vision's Battleground: Choose Your Champion

Transforming medical imaging with Transformers? A comparative review of key properties, current progresses, and future perspectives - ScienceDirect

PDF) How to Fine-Tune Vision Models with SGD

Our OOD accuracy results compared with the best reported numbers in